一、HashMap学习笔记
HashMap采用数组+链表的数据结构,只是在jdk1.7和1.8的实现上有所不同,下面,简单的分析一下,方便自己更加深刻的理解这种典型的key-value的数据结构。
1.1.jdk1.7实现原理简单分析
1.7的HashMap数据结构图
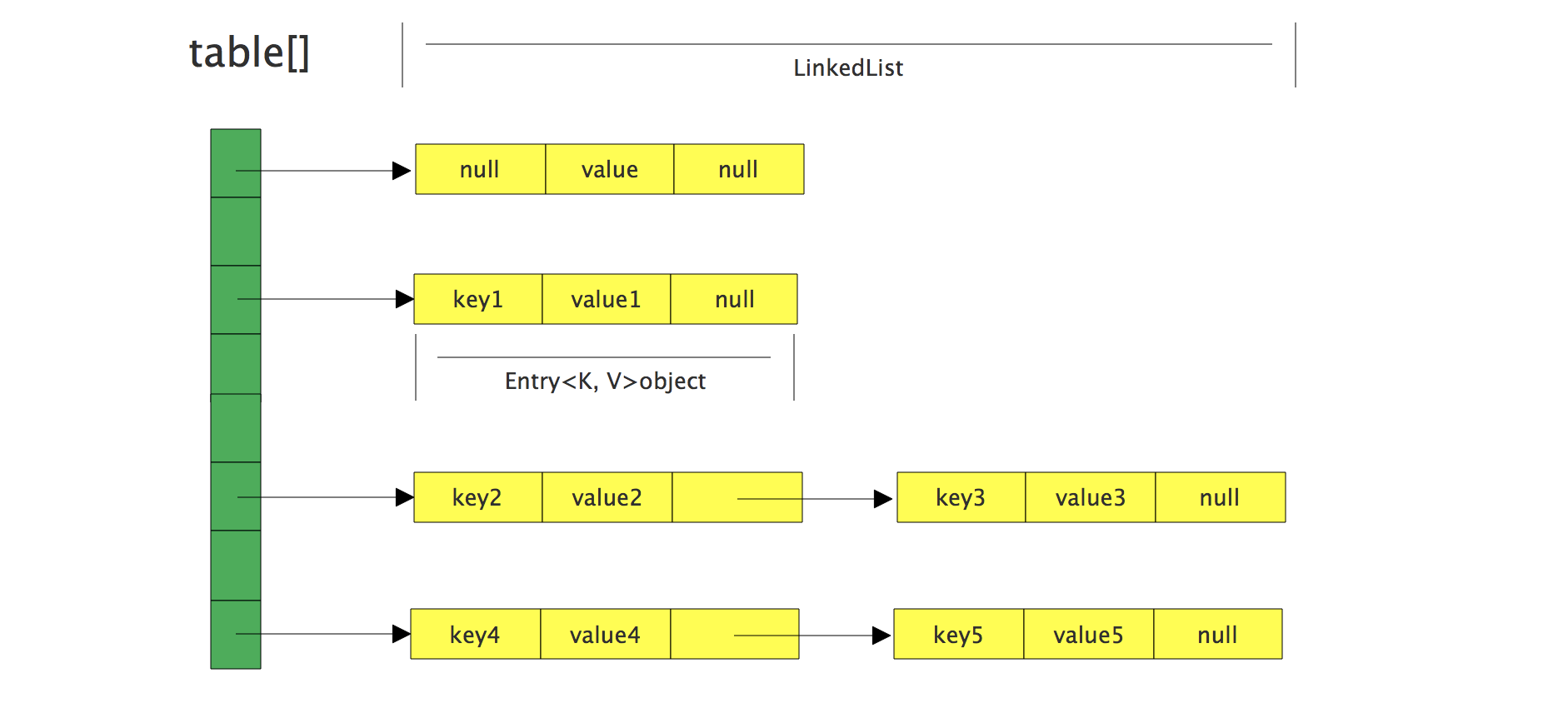
在jdk1.8之前,HashMap由数组 + 链表组成,也就是链表散列,数组是HashMap的主体,链表实则是为了解决哈希冲突而存在的,(拉链法解决哈希冲突) 。
HashMap 通过 key 的 hashCode 经过扰动函数处理过后得到 hash 值,然后通过 (n - 1) & hash 判断当前元素存放的位置(这里的 n 指的是数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。
所谓扰动函数指的就是 HashMap 的 hash 方法。使用 hash 方法也就是扰动函数是为了防止一些实现比较差的 hashCode() 方法 换句话说使用扰动函数之后可以减少碰撞。
所谓 “拉链法” 就是:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
1.7的HashMap类中的常量
1 | /** 初始化桶大小,HashMap底层是数组,这个是数组默认的大小 */ |
loadFactor负载因子
默认的HashMap的容量是16,负载因子是0.75,当我们在使用HashMap的时候,随着我们不断的put数据,当数量达到16 * 0.75 = 12的时候,就需要将当前的16进行扩容,而扩容就涉及到数据的复制,rehash等,就消耗性能,所谓的负载因子,也可以叫加载因子,用来控制数组存放数据的疏密程度,loadFactor越趋紧与1,说明数组中存放的entry越多,链表的长度就越长。所以,建议当我们知道HashMap的使用大小时,应该在初始化的时候指定大小,减少扩容带来的性能消耗。
loadFactor太大导致查找元素效率低,太小导致数组的利用率低,存放的数据会很分散。loadFactor的默认值为0.75f是官方给出的一个比较好的临界值。
threshold桶大小
threshold桶大小,也叫临界值,threshold = capacity \* loadFactor,当HashMap的Size>=threshold的时候,那么就要考虑对数组的扩增了,也就是说,这个的意思就是 threshold是衡量数组是否需要扩增的一个标准。
table存放数据的数组
table数组中存放的是Entry类型的数据,下面我们简单看看Entry的定义。
1 | static class Entry<K,V> implements Map.Entry<K,V> { |
Entry是一个内部类,其中的key就是写入的键,value就是写入的值,由于HashMap由数组+链表的形式,这里的next就是用于实现链表结构。hash存放的事当前key的hashcode值。
put()方法
1 | public V put(K key, V value) { |
新增一个Entry
1 | void addEntry(int hash, K key, V value, int bucketIndex) { |
put()方法简单将如下:

get()方法
1 | public V get(Object key) { |
1.2.jdk1.8实现原理简单分析
在jdk1.7中HashMap实现原理分析,我们知道当hash冲突很严重的时候,链表的长度就会很长,我们也知道数组和链表的优缺点,简单总结一下:
数组:数据存储是连续的,占用内存很大,所以空间复杂度较高,但是二分查找的时间复杂度为O(1),简单讲就是,数组寻址容易,插入和删除较为困难。
链表:存储区间零散,所以内存较为宽松,故空间复杂度较低,但是时间复杂的高,为O(n),简单讲就是,链表寻址困难,插入和删除较为容易。
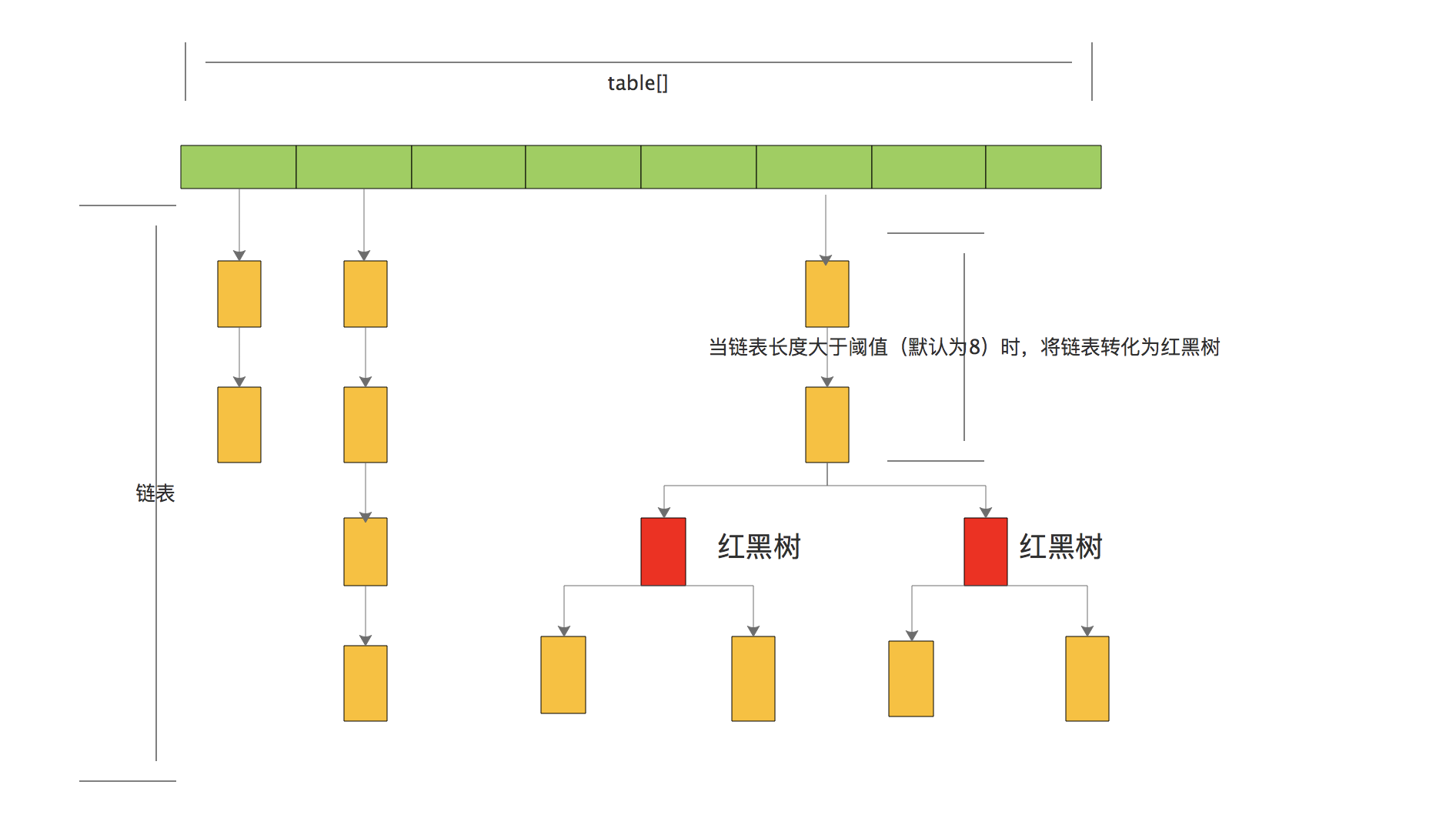
所以,在jdk1.8中,对HashMap的实现做了相应的修改,jdk1.8 以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)时,将链表转化为红黑树,以减少搜索时间。
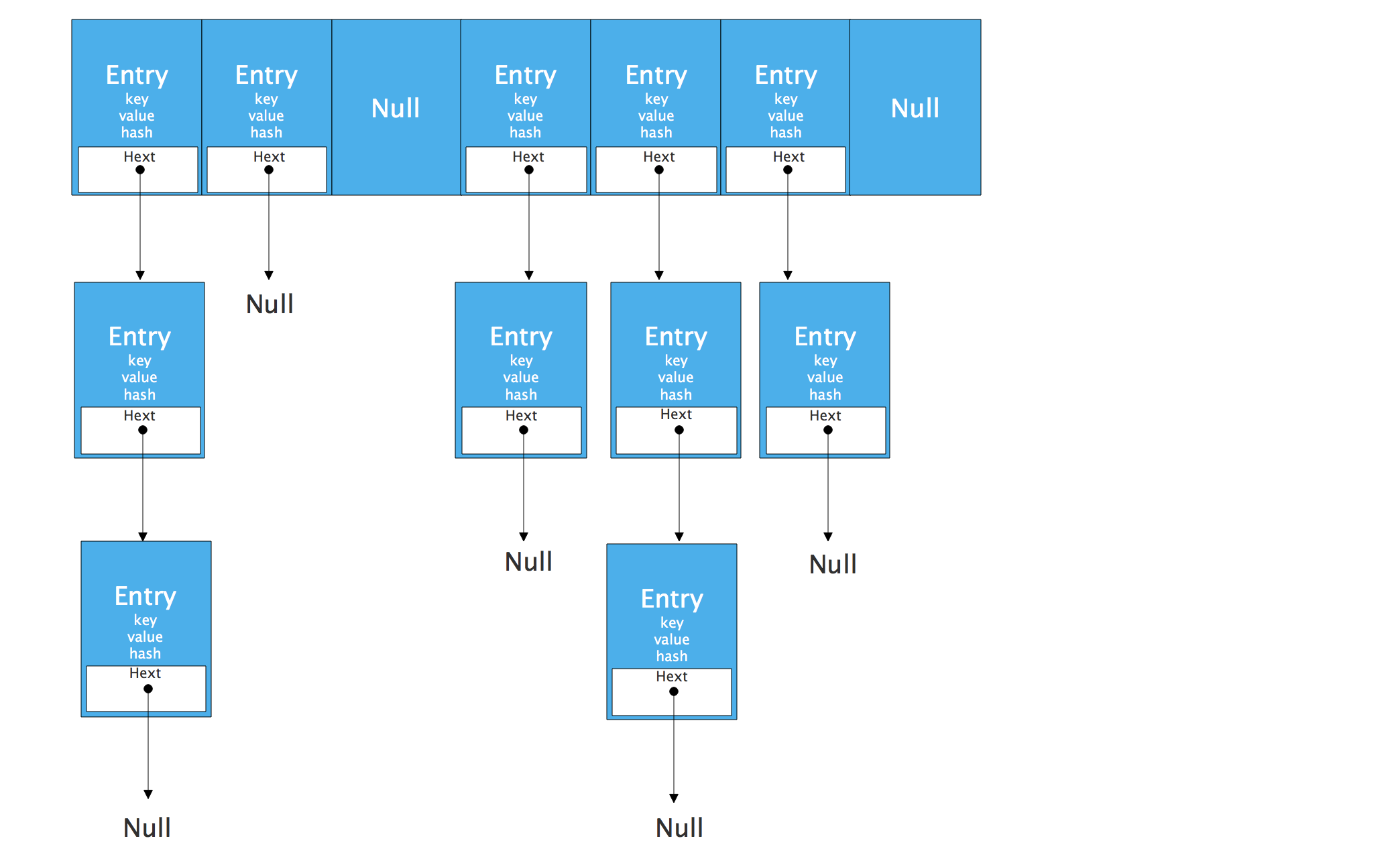
1.8的HashMap的数据结构图
1.8的HashMap类的常量
1 | /** 默认的初始容量16 */ |
对比1.7中的常量,我们就会发现1.8中做了如下的改变。
- 增加了
TREEIFY_THRESHOLD,当链表的长度超过这个值的时候,就会将链表转换红黑树。 Entry修改为Node,虽然Node的核心也是key、value、next。
Node类
1 | static class Node<K,V> implements Map.Entry<K,V> { |
树节点类
1 | static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> { |
put()方法
1 | public V put(K key, V value) { |
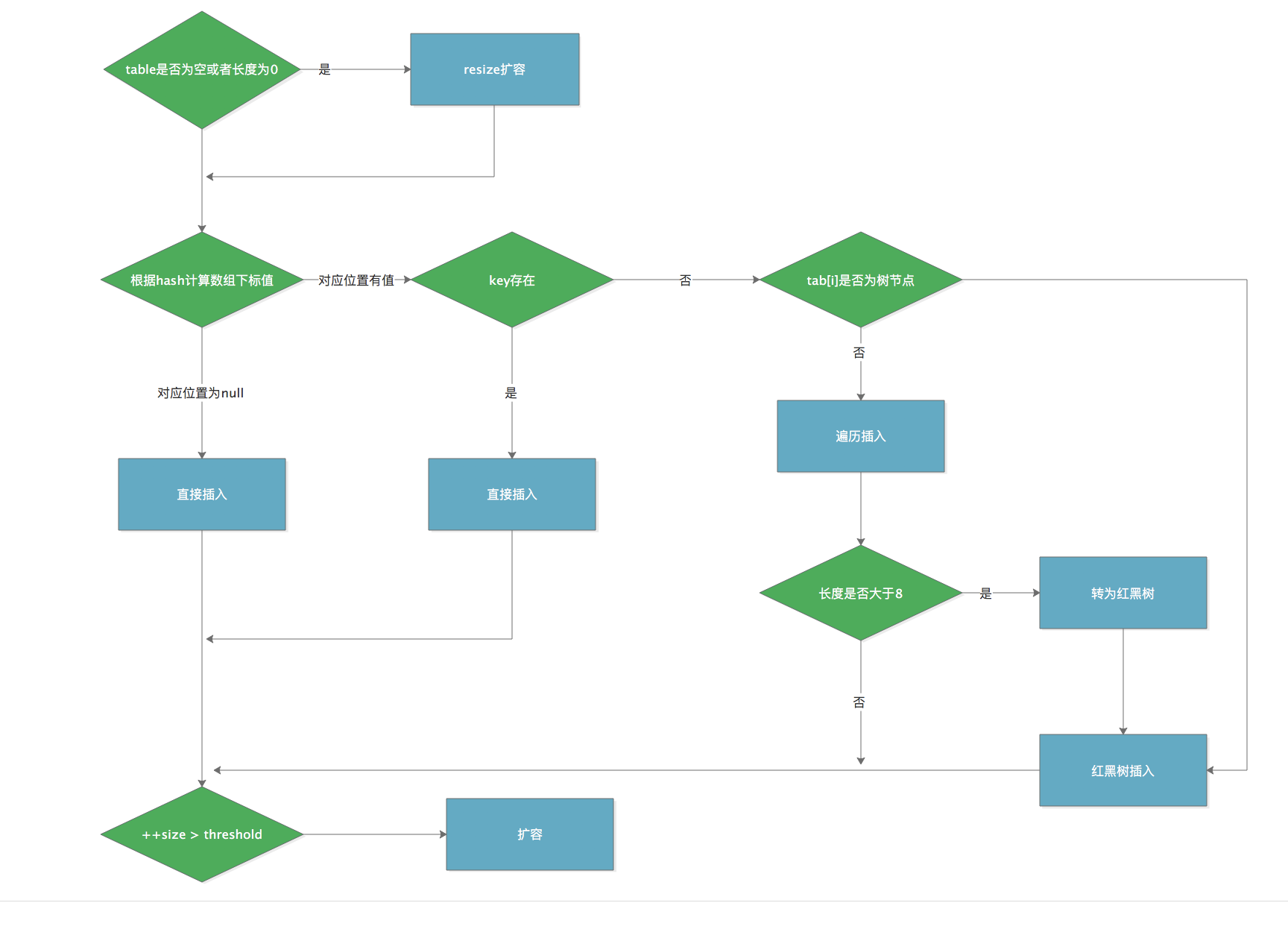
1 | final V putVal(int hash, K key, V value, boolean onlyIfAbsent, |
put方法图解
get()方法
1 | public V get(Object key) { |
1 | final Node<K,V> getNode(int hash, Object key) { |
小结
从上面的简单分析中,我们可以知道在jdk1.8之后,对HashMap的实现做了改变,主要在于将链表的长度超过临界值的时候,就将链表转为红黑树,利用红黑树的优点,可以更好的查找元素,使得查询的时间复杂度变为O(logn)
但是,jdk1.8并未有修改HashMap之前的线程安全问题,我们都知道HashMap是线程不安全的,涉及到线程安全的时候,我们应该使用ConcurrentHashMap,有关ConcurrentHashMap的知识将在下一片博客中学习,这里简单的分析一下,为什么HashMap会造成线程不安全尼?
1.3.HashMap线程不安全的原因
resize造成死循环
在1.7中,当数据put进HashMap的时候,都会比较和thredhold的大小,当超过临界值的时候,就会进行扩容操作,就会调用resize()方法。而resize()中调用了transfer方法。下面简单的看看transfer方法。
但是在1.8中,resize()方法的实现和1.7有一些不一样,没有使用transfer方法,可以说1.8中hashmap不会因为多线程put导致死循环,但是依然有其他的弊端,比如数据丢失等。因此多线程情况下还是建议使用concurrenthashma,
Jdk1.7中transfer方法如下:
1 | void transfer(Entry[] newTable, boolean rehash) { |
transfer方法的的作用就是:
- 对索引数组中的元素遍历
- 对链表上的每一个节点遍历:用 next 取得要转移那个元素的下一个,将 e 转移到新 Hash 表的头部,使用头插法插入节点。
- 循环2,直到链表节点全部转移
- 循环1,直到所有索引数组全部转移
转移的时候是逆序的。假如转移前链表顺序是1->2->3,那么转移后就会变成3->2->1。死锁问题不就是因为1->2的同时2->1造成的吗?所以,HashMap 的死锁问题就出在这个transfer()函数上。




